这篇文章主要介绍了一个通用的网站新闻页正文抽取组件libnpce库。
一、libnpce组件简介
新闻文章正文抽取News Passage Content Extractor (NPCE),是为抽取HTML中的新闻文章正文而设计的。
可用libnpce组件抽取新闻页面的如下字段信息:
(1)标题
(2)发布时间
(3)来源及其URL链接地址
(4)正文文本内容
(5)正文图片信息
(6)图片位置信息
二、编译链接
-
操作系统环境:
CentOS6~7
-
编译环境
gcc/g++ >=4.4
-
第三方依赖
无第三方依赖(依赖的boost、tidy、htmlcxx、jsoncpp等库已经通过源码集成在源代码中了)
- 程序结构
\ -include 头文件所在目录 -src 源程序所在目录 -test 测试和使用示例 -cgifile 用于进行CGI部署的程序 -parseapp 对APP正文抽取的组件封装 -python 为python语言调用封装的通用接口 -server 提供基于HTTP服务访问的RESTful接口 -Makefile -publish SERVER的发布版本 -readme.txt 说明文件 -bin 二进制文件生成目录 -run.sh 运行测试程序脚本 - 编译方法
git clone https://gitee.com/inrgihc/libnpce.git
cd libnpce/
make clean
make all
三、支持的集成方式
程序采用C++语言开发,提供C/C++的动态链接库、RESTfull的接口、python接口的调用集成:
- SO动态链接库的调用
当程序编译完成后会在bin/debug目录下生成libnpce.so动态链接库和libnpce.a静态链接库文件,集成所需的头文件请见 npce.h ,其中几个核心的接口函数如下:
/****************************************************************/
/* 函数名:npce* npce_open(const int type=NPCE_ET_TITLE|NPCE_ET_CONTENT);
* 功能:创建一个NPCE句柄
* @param: type [in] ,整型,要抽取的正文元素类型
* @return:成功返回句柄(非零),失败返回NULL
* */
NPCE_API npce* npce_open(const int type=NPCE_ET_TITLE|NPCE_ET_CONTENT);
/*函数名:int npce_setopt(npce * h, NpceOpt opt, ...);
*功能:设置选项参数,详见NpceOpt的定义注释部分
*@param: h [in] ,npce类型,句柄
*@param: opt [in] , NpceOpt , 参数类型
*@return:成功返回0,其他为失败。
**/
NPCE_API NpceCode npce_setopt(npce * h, NpceOpt opt, ...);
/* 函数名:int npce_getopt(npce * h, NpceOpt opt, ...);
*功能:获取选项参数,详见NpceOpt的定义注释部分
*@param: h [in] ,npce类型,句柄
*@param: opt [in] , NpceOpt , 参数类型
*@return:成功返回0,其他为失败。
**/
NPCE_API NpceCode npce_getopt(npce * h, NpceOpt opt, ...);
/* 函数名:int npce_perform(npce * h,const char *html,const char *url);
*功能:执行正文抽取
*@param: h [in] ,npce类型,句柄
*@param: html [in] , 字符串,要抽取的HTML源码,需为UTF-8编码
*@param: url [in] , 字符串, HTML源码的URL绝对路径
*@return:成功返回0,其他为失败。
**/
NPCE_API NpceCode npce_perform(npce * h,const char *html,const char *url);
/* 函数名:int npce_result(npce * h,NpceResult &result);
*功能:当npce_perform执行成功时获取正文结果
*@param: h [in] ,npce类型,句柄
*@param: result [out] , NpceResult,正文结果
*@return:成功返回0,其他为失败。
**/
NPCE_API NpceCode npce_result(npce * h,NpceResult &result);
/* 函数名:string npce_error(npce * h);
*功能:获取最后一次的错误信息
*@param: h [in] ,npce类型,句柄、
*@return:返回错误的字符串信息
**/
NPCE_API string npce_error(npce * h);
/*函数名:void npce_close(npce* h);
*功能: 关闭NPCE句柄,释放内存空间
*说明:请勿多次释放
*@param: h [in] ,npce类型,句柄、
**/
NPCE_API void npce_close(npce* h);
调用的示例代码如下:
int main(int argc,char *argv[])
{
if(argc<2)
{
cout<<"Usage:"<<argv[0]<<" [url]"<<endl;
return 1;
}
string url=argv[1];//从命令行中获取待抽取的url地址
CUrlDownload loader;
string html;
vector< pair<string,string> >::iterator it;
if(loader.Download2Mem(url,html,true,50)) //根据url下载到html源码至变量html中
{
npce* h=npce_open(NPCE_ET_TITLE|NPCE_ET_CONTENT|NPCE_ET_PUBTIME|NPCE_ET_SOURCE|NPCE_ET_IMAGES);
if(h)
{
npce_setopt(h,NPCEOPT_MARKED_IMG,1); //是否标记图片的位置
npce_setopt(h,NPCEOPT_LINK_ANCHOR,0); //是否抽取链接信息
npce_setopt(h,NPCEOPT_HTML_TIDY,0); //是否使用tity库进行html整理
npce_setopt(h,NPCEOPT_FILE_FILTER,"filter.txt"); //设置过滤词所在的文件
}
//执行正文抽取
if(h && 0==npce_perform(h,html.c_str(),url.c_str()))
{
//输出打印抽取结果
NpceResult result;
if(0==npce_result(h,result))
{
cout<<"Title:"<<result.title<<endl;
cout<<"Source:"<<result.source<<endl;
cout<<"SrcUrl:"<<result.srcurl<<endl;
cout<<"Pubtime:"<<UTC2String(result.pubtime)<<endl;
cout<<"Content:"<<endl<<result.content<<endl;
cout<<"Images:"<<endl;
int index=0;
vector< pair<string,string> >::iterator it;
for(it=result.imglist.begin();it!=result.imglist.end();++it)
{
cout<<"["<<++index<<"]"<<it->first<<endl;
}
}
npce_close(h);
}
else
{
cout<<"Extract error:"<<npce_error(h)<<endl;
}
}
else{
cout<<"Download error!"<<endl;
}
return 0;
}
- RESTful服务调用的接口
(1)服务模块介绍与编译
RESTfull的服务基于开源的mongoose进行了http服务的对libnpce.a进行了封装,需要如下依赖:
-lcodeconv -liconv -lcurl -lcares -lrt -lz -lssl -lcrypto
编译方法如下:
cd server/
make clean
make all
(2)服务部署与启动停止
在libnpce/public目录下提供了httpd_npce_server_1.0.36_bin.tar.gz可执行包,在httpd_npce_server目录下的readme.txt描述了详细的使用说明,使用方法如下:
cd libnpce/publish/
tar zxvf httpd_npce_server_1.0.36_bin.tar.gz
cd httpd_npce_server/
tree .
.
├── httpd_npce_app
├── pronpced.sh
├── readme.txt
├── shutdown.sh
└── startup.sh
启动服务: ./startup.sh 停止服务: ./shutdown.sh
(3)服务的调用
服务遵循HTTP协议访问,参数提交以POST方式提交,详细参数设置如下:
----------------------------------------------------------------------
| 参数名称 | 默认值 | 参数解释
----------------------------------------------------------------------
| url | 不允许为空值 | 要抽取正文信息的URL(需URL编码)
----------------------------------------------------------------------
| img | 0 | 是否抽取正文中的图片,1为是,0为否
----------------------------------------------------------------------
| flg | 0 | 是否在正文中标记图片,1为是,0为否
----------------------------------------------------------------------
注:图片在正文中的位置标记方式为”{IMG:N}”,这里N为图片的序号。
下面以用CURL命令对服务进行调用:
a)WEB端URL抽取
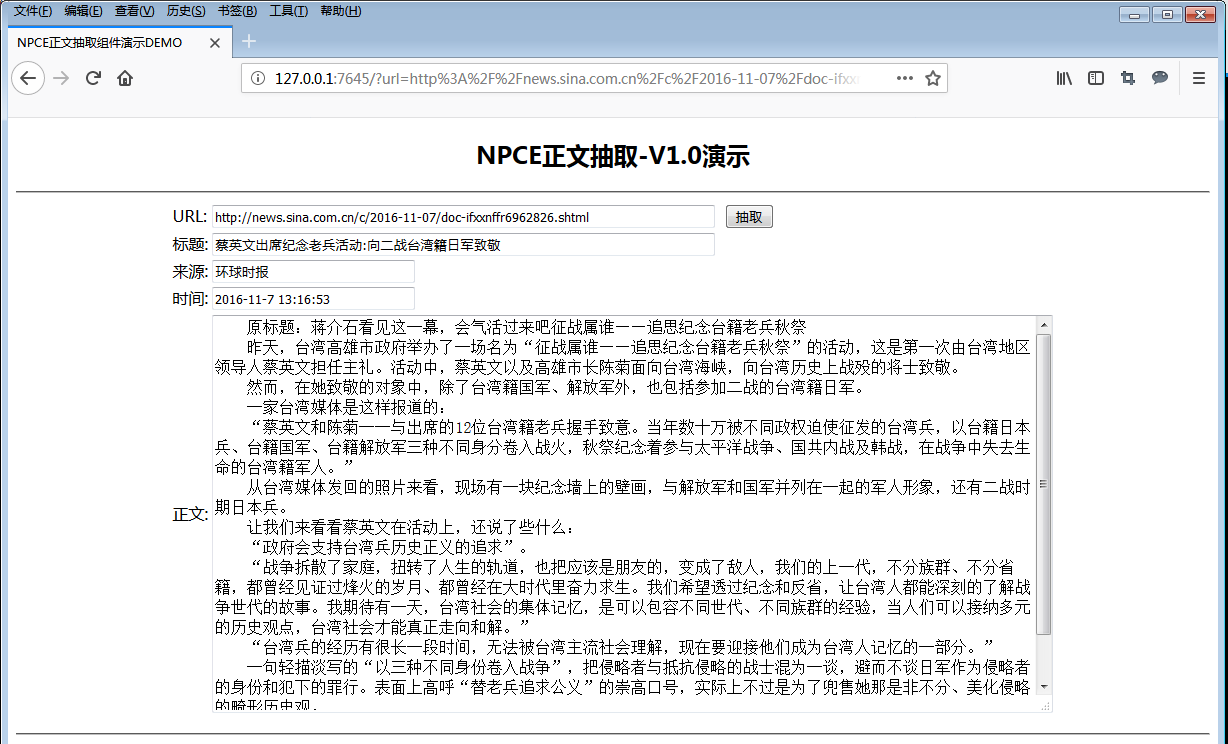
$ curl "http://127.0.0.1:7654/npce" -d "img=1&flg=1&url=http://news.sina.com.cn/c/2016-11-07/doc-ifxxnffr6962826.shtml"
{
"status": 0,
"errmsg": "Success",
"doc": {
"url": "http://news.sina.com.cn/c/2016-11-07/doc-ifxxnffr6962826.shtml",
"title": "蔡英文出席纪念老兵活动:向二战台湾籍日军致敬",
"pubtime": "2016-11-7 13:16:53",
"source": "环球时报",
"content": " 原标题:蒋介石看见这一幕,会气活过来吧\n{IMG:1}\n征战属谁——追思纪念台籍老兵秋祭 \n 昨天,台湾高雄市政府举办了一场名为“征战属谁——追思纪念台籍老兵秋祭”的活动,这是第一次由台湾地区领导人蔡英文担任主礼。活动中,蔡英文以及高雄市长陈菊面向台湾海峡,向台湾历史上战殁的将士致敬。\n 然而,在她致敬的对象中,除了台湾籍国军、解放军外,也包括参加二战的台湾籍日军。\n 一家台湾媒体是这样报道的:\n “蔡英文和陈菊一一与出席的12位台湾籍老兵握手致意。当年数十万被不同政权迫使征发的台湾兵,以台籍日本兵、台籍国军、台籍解放军三种不同身分卷入战火,秋祭纪念着参与太平洋战争、国共内战及韩战,在战争中失去生命的台湾籍军人。”\n 从台湾媒体发回的照片来看,现场有一块纪念墙上的壁画,与解放军和国军并列在一起的军人形象,还有二战时期日本兵。\n 让我们来看看蔡英文在活动上,还说了些什么:\n “政府会支持台湾兵历史正义的追求”。\n “战争拆散了家庭,扭转了人生的轨道,也把应该是朋友的,变成了敌人,我们的上一代,不分族群、不分省籍,都曾经见证过烽火的岁月、都曾经在大时代里奋力求生。我们希望透过纪念和反省,让台湾人都能深刻的了解战争世代的故事。我期待有一天,台湾社会的集体记忆,是可以包容不同世代、不同族群的经验,当人们可以接纳多元的历史观点,台湾社会才能真正走向和解。”\n “台湾兵的经历有很长一段时间,无法被台湾主流社会理解,现在要迎接他们成为台湾人记忆的一部分。”\n 一句轻描淡写的“以三种不同身份卷入战争”,把侵略者与抵抗侵略的战士混为一谈,避而不谈日军作为侵略者的身份和犯下的罪行。表面上高呼“替老兵追求公义”的崇高口号,实际上不过是为了兜售她那是非不分、美化侵略的畸形历史观。\n 不知道蒋介石泉下有知,看到这一幕,会作何感想。\n责任编辑:向昌明 SN123",
"images": [{
"img_id": 1,
"img_src": "http://n.sinaimg.cn/translate/20161107/9Esa-fxxnrss2845950.jpg"
}]
}
}
注:在content内有{IMG:1}字样的图片位置标注。
b)移动端URL抽取
当前针对搜狐新闻APP和网易新闻APP提供抽取功能,同时支持HTTP头部重定位跳转
$ curl "http://127.0.0.1:7654/npce" -d "img=1&flg=1&url=http://3g.k.sohu.com/t/n163449101"
{
"status": 0,
"errmsg": "Success",
"doc": {
"url": "http://3g.k.sohu.com/t/n163449101",
"title": "一不注意把哥们的车身碰出凹痕!怎么办?",
"pubtime": "2016-11-8 0:0:0",
"source": "汽车装具网",
"content":"\n 日常用车中,爱车遭受小刮小蹭在所难免。而为了车辆的美观我们不得不把车送去维修。\n 维修过程相信大家一定清楚了,当然价格肯定也是很多朋友所关心的,如果在速度占优的情况下收费相对合理,肯定是件值得推荐的事情。
\n{IMG:1}
\n 钣金喷漆修复\n 如果车辆出现凹陷一般的修理厂和4S店采取的方式都是钣金、喷漆。首先是用锤子或者焊接将凹陷部位恢复原状;钣金后用腻子将不平整的区域,修复平整;再用不同型号的砂纸打磨来修整腻子的凹凸面;最后就是调色、喷漆和烤漆。这种方法并不是对局部进行修复或者喷漆,为了保证漆面颜色一致,会对零件整个进行喷漆,比如车门有一个凹痕,就需要把整个车门进行喷漆。\n 钣金喷漆的这种修复方式,一般需要1到2天才能完成,价格最低也要300左右。并且还会损害原车车漆,甚至还会出现一定的色差。正是因为如此繁琐的修复过程才让一些车主,选择置之不理。\n 凹痕修复技术\n 需要靠专业工具由内部向外部顶起,外部的凹陷边缘以及凸起部分需要用小锤子进行敲砸,并且主要是依靠敲砸凹陷周围,使凹陷棱角处的受力进行分散,来达到整体修复的目的。简单说,维修师傅就是要根据经验来判断造成此伤痕的外力的角度从而通过反方向的逆向“给力”来修复伤痕。这种技术已经比较的成熟,从视觉上看,看不出这是一辆修复过的车。\n 这种修复方式最大的优势就是,免去了钣金喷漆的过程,不仅耗时更短、费用更低,还可以保证原厂车漆不受到损害。但是这种修复方式的效果也和维修师傅的技术有着非常直接的关系,如果技术不到位,很可能坑坑洼洼效果很差。\n 当然这种修复方式也不是万能的,如果漆面已经严重破损或是凹痕边缘棱角过于尖锐,甚至出现了死角,一般都不建议采用这种方式进行修复。而除了以上两种情况,大部分凹痕一般都可以通过快速修改进行快速修理。\n 某宝的凹陷修复工具\n 这事即使在网上自己购买的汽车凹陷修复工具,成本非常低也就是几十块钱,并且包邮。用干净的湿布清洁凹痕部分;用热熔胶固定一个合适的牵引垫片,轻轻压住,直至热熔胶固化粘牢;把牵引拉力桥中间的孔对准粘牢的牵引垫片杆,把螺母旋钮套在牵引垫片杆,慢慢旋紧,直到把凹痕部分拉到同周围的表面齐平即可。\n 但是这种办法的成功率不是太高,平缓的凹痕好修复,出现较深的凹痕劝大家还是要去钣金。如果凹陷的部位之前经历过钣金和喷漆后,漆不稳,很有可能会将车漆扯下来。如果是平缓的凹痕完全可以自己试一下,毕竟这个成本很低。\n 现在凹陷修复的方式越来越多,某宝上都已经出现了自己DIY的修复方式,并且大多数的修复工具也就30元左右,相比维修店的凹陷修复更加便宜。维修店的凹陷修复技术虽然“神奇”,但是如果技术不够硬的话,很有可能造成漆面的裂痕,并且稳定性也有待考究。最原始的方式当然就是钣金喷漆了,但是费时、费力还费钱,不过在效果上是毋容置疑的。\n 有朋友会提出疑问,我的车上了保险,车身有凹痕我走保险不就可以了吗,何必费劲去做凹痕修复呢?\n 这么说也不错,不过您考虑到出险次数与保险费挂钩的情况了吗?如果您过去一年内出险1次,那么保险费的折扣就会少很多。根据现有的规定,您上一年没有出险的话,下一年保费可以享受8.5折,而出了一次险这个折扣就不享受了!\n 一不注意把哥们的车身碰出凹痕!怎么办?原文地址:http://news.zgqczj.com/349/52232.html",
"images": [{
"img_id": 1,
"img_src":
"http://n1.itc.cn/img7/adapt/wb/recom/2016/11/08/147858801279851221_120_120.JPEG"
}]
}
}
注:在content内有{IMG:1}字样的图片位置标注。
- python接口的调用
在libnpce/python目录下提供了对libnpce的python调用的封装,编译前需要安装Python-devel,安装完成后,可使用如下命令编译此部分的代码:
cd libnpce/python/
make clean
make all
python调用的示例代码如下:
import urllib
import urllib2
import sys
import libgolaxynpce
url=sys.argv[1]
req=urllib2.Request(url)
file = urllib2.urlopen(req)
html=file.read()
ret=libgolaxynpce.extract(url,html,0,0)
print ret
四、演示服务
到页面:下载地址下载httpd_npce_py-v1.0-bin.tar.gz文件,在centos环境下解压,然后执行startup.sh命令启动服务,打开浏览器访问服务器上的服务:
http://127.0.0.1:7645
在页面中的URL栏中粘贴一个新闻页面的URL地址,然后点击右侧的“抽取”按钮查看效果,我的截图如下: